虽说标题写的是SSL性能测试,但其实是不是SSL都无关紧要,只是测试的配置有所不同罢了。相比具体某个指标的测试方法,我们更应该关注的是性能测试的一般原则。具体的测试指标可能随着测试业务、测试环境而千差万别,但是核心的测试方法论是不变的。
因为笔者对SSL的性能测试比较熟悉,所以将以SSL性能测试主要关注的3个指标为例进行分享:每秒新建连接数、最大吞吐量、最大连接数。
性能测试方法论
主动式测试
之所以把这一点放在最前面,是因为它实在太重要了。
主动式测试,与之相对的就是被动式测试。大部分人做性能测试可能就是跑个命令或者脚本之类的,然后读个结果就完事了。这种测试方式就是典型的被动式测试。
被动式测试:你想测试A,但实际测试了B,最后得出的结论是你测试了C
被动式测试经常会导致各种问题,基于错误的结果得出错误结论,进而作出错误的判断和选择。更要命的是测试者自己并不自知。
主动式测试可以帮助你准确地测试真正的目标,并正确地理解测试结果。你在一开始多花一点心力,可以省去以后多得多的时间甚至金钱。
那么怎么样才算主动式测试呢?问自己如下两个问题:
- 你能否确认正在测试的是真正的测试目标?
- 你能否解释测试结果,即瓶颈是什么?
所以主动式测试不是跑个命令就万事大吉,可以去喝咖啡了,而是需要你在测试前、测试中、测试后都进行分析。而且主动式测试通常也不是一次搞定的,根据测试的情况可能需要对测试环境、测试工具等进行不断的调整。
- 测试前:
- 明确测试对象,即你究竟要测试什么东西。这很关键,你必须清晰地知道自己在测什么,才能采用合理的配置,做出正确的分析判断。后面所有的配置修改、分析调整都是为了这个测试目标服务的:使测试值尽可能的接近理想值。
- 你需要了解你的测试工具,知道它是怎么工作的。通常我们使用的测试工具都是开源的,你可以借助源码进行分析。
- 你需要提前分析配置,包括的你的测试环境、测试对象、测试工具等。
- 即使你提前分析了配置,可能不免还是会有一些遗漏或未知的,尤其是当你还没什么经验的时候。没关系,因为我们是主动式测试,问题会在后面测试时被暴露和发现,到时候再逐个击破即可。
- 测试中:
- 借助其他工具确认你正在测试真正的目标
- 借助其他工具分析系统情况(如CPU、内存、I/O、socket等),识别真正的瓶颈。
- 如果发现测试的不是真正的目标,调整后重新开始。
- 如果瓶颈不如预期,需要分析确认原因,然后调整之后重新开始测试。
- 测试后:
- 最终你确认自己测试了真正的目标,并得到了一个可以合理解释的测试值。此时并不是记录这一个值就可以了,单个数字是没有任何意义的,它只有在你这个特定的测试环境、测试配置以及其他观测工具提供的证据的加持下才是有意义的。所以这些都是测试结果的一部分,需要一并记录保存。
- 尝试进行优化,当前这可能需要你对测试系统或测试对象有足够的了解。
例子
就以SSL新建连接数测试为例,简单介绍下思路:
- 测试前:
- 确定测试对象,因为是要测SSL新建连接数的TPS,所以需要确保CPU主要是消耗在完整SSL握手的过程上。也就是说,不能让tcp成为瓶颈、不能会话重用、http不能是长连接、http层业务的CPU消耗也要越小越好等等。。。
- 经过调查研究决定使用wrk作为测试工具
- 了解它的测试模型是怎么样的,各个选项表示什么
- 修改Nginx配置,保证是测试正确的目标。因为影响性能的指标项非常多,建议可以分层进行考虑:nginx核心、tcp层、ssl层、http层等。资源限制类的配置通常有系统级别的和进程级别的,进程级别的不能超过系统的。而Nginx配置的是进程级别的,所以需要保证系统的已经设置的足够大了。
- 因为SSL新建连接也涉及TCP新建连接,所以内核网络相关的参数也需要关注,尤其是TCP建连和断连阶段相关的参数,如backlog和timewait。
- 随着流量的增大,软中断和网卡可能会成为瓶颈,需要进行相应配置
- 测试中:
- 通过抓包进行确认测试的是SSL新建连接。如果你偷懒忽略了这一步,可能就无法发现它其实默认进行了会话重用了、或者双向认证测试成了单向认证、又或者是卡在tcp建立连接上等等。
- 通过工具观察系统情况(CPU、内存、IO、socket等),你可能会发现TPS到一定的值就上不去了,而CPU并没有满。这个时候就需要借助各种工具进行分析排查,原因可能各种各样。可能是你的worker最大连接数设得太小、可能是backlog设置得太小、可能是客户端压力不够、可能是网络中有个百兆交换机、也可能是timewait的原因、如果有后端还可能是后端到瓶颈了。。。
- 定位到问题之后进行相应调整再重新测试,可能又会发现的新的问题和瓶颈,就这样进行不断优化迭代。最终可能你发现服务端的CPU满了,这是符合预期的,因为SSL握手是一个CPU密集型的操作。如果有条件最好对系统做个采样看看火焰图中的CPU都消耗在了哪里,有没有异常的地方。
- 测试后:
- 经过多次调整尝试,最终你认为测试值已经足够接近真实值,这个测试值,与测试环境、测试配置以及观测证据一并组成了最终的测试结果。
一些建议
接下来给出一些常用的建议,遵循这些建议,貌似增加了工作量,其实最终会提升你的效率,减少出错和绕弯的可能性,而且还方便后续复现与回看,下次再进行类似测试时也可以省去很多重复的工作。
- 尽可能详细的记录
- 记录软硬件配置
- 保存并整理测试结果
- 写下命令行调用,避免每次手输
- 记录查询和研究的文档和url等
- 自动执行重复任务
- 测试任务尽量自动化,既减小出错的可能,也减小了测试负担
- 尽量选用低开销的工具
- 使我们的测试值更接近真实值
- 使用多个工具
- 必要时可能需使用多个工具进行相互验证,排除工具本身的问题
- 确定基线和目标
- 单个值通常没有太大的意义,不知道它是好是坏,没有对比就没有伤害
- 分离问题、对比、控制变量
- 这是定位问题的基本思路
- 做了优化之后需要重新进行完整测试
- 因为不确定是否会对其他项目产生负面影响
关键配置梳理
首先从整体上先介绍下关键的配置
SSL新建连接
服务端调优
- nginx配置
- cpu亲和性
- 文件句柄限制
- backlog、reuseport、deferred
- tcp_nopush/tcp_nodelay
- SSL完整握手、无会话重用、HTTP短连接
- 内核参数(主要backlog、timewait、文件句柄限制)
- irq绑定
客户端调优
- 内核参数(主要timewait、文件句柄限制、端口)
- irq绑定
- 配置多ip地址(根据需要,如端口数不够或负载均衡需要)
吞吐量
只需要在SSL新建连接基础上稍作调整即可
- 服务端改成http长连接,长连接超时时间设置大
- 客户端请求时也改成长连接,请求1MB大文件
最大并发数
最大并发主要跟内存相关,受机器总内存限制。如果想让最大并发数尽可能高,就需要将各种buffer的size调小,同时需要将各超时时间设大,因为最大并发通常需要测试很长时间。
- http长连接
- worker_connections增大到目标值
- 各超时时间设大(recv/send)
- 各buffer设小(tcp/ssl/http)
- 客户端长连接,请求小文件,将压力限制为一个较小的值(可以使用wrk2的
-R选项)
接下来具体介绍各部分,相关的配置文件和脚本等可见Git仓库ssl-perf-test。
需要着重提醒的是,测试的配置并不是一成不变的,需要在理解配置含义的基础上,结合自身的测试需求合理进行配置。
配置详解
Nginx配置
下面的进行SSL新建连接测试时的主要的配置nginx-tps.conf:
1 | worker_priority -1·0; |
main
worker_processes
一般设成auto就可以,会自动根据系统CPU核心数进行设置
worker_cpu_affinity
一般auto就可以,会自动每个进程绑定一个核
worker_rlimit_nofile
设置进程能打开的最大文件数目,底层是设置的RLIMIT_NOFILE,不能超过hard nofile
worker_priority
设置进程的优先级,跟nice命令干的事情差不多,值越小优先级越高。
error_log
把日志配置也列进来注意是为了提醒大家不要忘记修改
event
worker_connections
进程连接数一定要足够,但是也不要无脑设成超大的一个值,因为这些连接的内存在启动时就会分配,可能会导致内存不足。另外提一下,这是整个worker的连接数,包括了下游和上游。
multi_accept
默认关闭时,进程一次只accept一个连接;打开的时候进程会一次性accept所有已经就绪的连接。这个配置需要根据具体测试场景选择,一般保持默认关闭。
accept_mutex
打开时每个worker轮流接收新连接,关闭时则所有worker都会收到新连接通知(即所谓的惊群效应)。如果新连接数很少,会浪费系统资源。注意当使用reuseport的时候就没有这个配置什么事了,因为内核已经做了负载均衡了。这个配置是否打开,需要根据实际的负载情况实测确定。
http
access_log
性能测试时日志一般选择关闭
listen
listen有很多附加参数,可以配置一些socket选项
reuseport
对应
SO_REUSEPORT选项,多个worker进程创建独立的监听套接字,允许内核在worker进程间对连接的连接进行负载均衡。deferred
对应
TCP_DEFER_ACCEPT选项,可以推迟连接就绪的时间,只有当收到客户端发来的应用数据时才可以accept,可以稍微减小服务端的开销。backlog
设置listen全连接队列大小,不能超过系统
net.core.somaxconn的限制。这个需要足够大,否则会影响新建连接的速度。
keepalive_requests/keepalive_time
这两个分别设置http长连接的最大请求数和超时时间,根据实际测试指标选择是否启动
sendfile
是否使用sendfile()系统调用,可以直接在内核完成文件的发送,不需要再到用户态转一手
tcp_nopush
只有使用sendfile时才打开这个,对应Linux上的
TCP_CORK选项,响应头和文件开头在一个包中发送,文件以满包发送,提升网络效率。tcp_nodelay
对应
TCP_NODELAY选项,该选项是针对Nagle算法(在发出去的数据还未被确认前,把新的小数据先保存起来,等到凑满一个MSS或者收到了对方的确认后再发送)。linger_close/linger_time/linger_timeout
这几个控制在关闭服务端连接前是否等待和处理额外数据,以及等待的时间。
ssl_session_cache/ssl_session_timeout/ssl_session_tickets
这几个参数控制是否启用SSL会话重用以及超时时间,根据测试指标确定
ssl_verify_client/ssl_client_certificate
是否进行SSL双向认证,根据测试需求而定
ssl_buffer_size
发送数据时的SSL buffer大小,我们知道数据块长度越大,对称加密速度越快,所以这个默认值较大。但是如果你很关心第一个字节到达时间的话,最好将这个配置改小一点。
proxy_cache/proxy_cache_path
静态文件使用cache可以提高性能
client和proxy buffer相关配置
根据应用数据情况以及实际网络情况,client和proxy buffer相关的配置也可能影响性能。
内核参数与网络配置
与网络和tcp相关的内核参数非常多,对于我们的测试最主要的是backlog、timeout、文件句柄和端口。我一般修改如下这些参数,如果你的测试有其他需要或者遇到了其他的瓶颈,可以进行添加和修改。
1 |
|
为了方便在测试之后对系统配置进行还原,建议在修改前先保存原有配置。我这边写了一个简单的脚本,tune.sh中会自动执行store.sh保存你将要修改的配置到recover.sh中,在测试完成后执recover.sh即可恢复原先配置。
1 | # 在测试前修改配置,tune.sh中会自动调用store.sh保存 |
注意客户端和服务端关心的参数并不完全相同,比如服务端一般对端口数没有要求,客户端对backlog没有要求。一般情况下图方便直接全部改了问题也不大。
客户端虚拟ip
有时候客户端可能需要多个ip地址进行测试,下面的脚本setip.sh根据测试机器的CPU核数在一个网卡上设置对应个数的ip地址
1 |
|
删除IP可以通过对应的脚本delip.sh。
客户端测试脚本
这里的客户端使用wrk2,为了方便测试,写了几个简单的脚本,test-tps.sh用于测试新建连接,test-tpt.sh用于测试吞吐量,test-max.sh用于测试最大并发连接,test-rps.sh用于测试长连接的HTTP业务。下面是新建连接的脚本,其他几个也是类似:
1 |
|
为了最大化客户端的性能,我们使用了taskset将每个wrk2进程绑定到一个单独的CPU上,减少上下文切换带来的开销。不过这样每个wrk2实例都会打印一个测试结果,不方便进行观看和统计,所以写了一个脚本test.sh自动计算总和。
1 |
|
使用方法如下,参数中指定具体的测试(tps|tpt|max|rps)即可。
1 | $ ./test.sh tps |
服务端网卡bonding
有时候单个网口的流量到了瓶颈,可能需要对多个网口进行绑定以达到流量翻倍的效果。下面的脚本将eth2、eth3、eth4、eth5这4个网卡绑定到bond0上。
这里服务端和客户端都设置成了模式0,即roundrobin模式的负载均衡。
1 |
|
关于bonding可以参考这里
网卡队列及irq
在实际测试中,你可能会发现某些个CPU上的si特别高,成为了性能瓶颈。这时候就需要将网卡队列分配到不同CPU核上进行软中断的处理。如果客户端也碰到了类似问题,那么也需要进行类似操作。
为了方便测试,我写了一个脚本irqbind.sh可以自动进行网卡中断号的绑定及RPS的设置,使用方法如下:
1 | # 查看 |
1 |
|
下面介绍下手动进行设置的流程,以对脚本中的操作有所了解:
网卡中断号绑定到CPU
irqbalance服务可以帮你绑定中断号,不过它是动态变化的,如果你对irqbalance的效果不满意,或者想静态绑定,也可以自己手动进行绑定。操作步骤如下:
cat /proc/interrupts查看对应网卡的中断号下面的218-249就是eth11这个网卡对应的中断号,该网卡拥有32个队列
1
2
3
4
5
6
7
8
9
10
11218: 17094773 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 22 0 0 0 0 12697 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth11-TxRx-0
219: 3119 13271410 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth11-TxRx-1
220: 2385 0 13265837 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth11-TxRx-2
221: 23 0 0 13290114 0 0 0 0 0 0 0 0 2064 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth11-TxRx-3
...
...
245: 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 2000 6603326 0 0 0 0 0 0 0 149556 0 0 0 0 IR-PCI-MSI-edge eth11-TxRx-27
246: 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 6869437 0 0 2000 IR-PCI-MSI-edge eth11-TxRx-28
247: 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 6846871 2000 0 IR-PCI-MSI-edge eth11-TxRx-29
248: 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 2000 6937093 0 IR-PCI-MSI-edge eth11-TxRx-30
249: 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 2000 0 0 6837127 IR-PCI-MSI-edge eth11-TxRx-31接下来将中断号绑定到CPU核上
示例中218号中断绑定到1号CPU,以此类推
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
echo 00000001 > /proc/irq/218/smp_affinity
echo 00000002 > /proc/irq/219/smp_affinity
echo 00000004 > /proc/irq/220/smp_affinity
echo 00000008 > /proc/irq/221/smp_affinity
echo 00000010 > /proc/irq/222/smp_affinity
echo 00000020 > /proc/irq/223/smp_affinity
echo 00000040 > /proc/irq/224/smp_affinity
echo 00000080 > /proc/irq/225/smp_affinity
# ...
echo 01000000 > /proc/irq/242/smp_affinity
echo 02000000 > /proc/irq/243/smp_affinity
echo 04000000 > /proc/irq/244/smp_affinity
echo 08000000 > /proc/irq/245/smp_affinity
echo 10000000 > /proc/irq/246/smp_affinity
echo 20000000 > /proc/irq/247/smp_affinity
echo 40000000 > /proc/irq/248/smp_affinity
echo 80000000 > /proc/irq/249/smp_affinity
RPS
有时候你的网卡不支持多队列、或者队列数少于CPU核心数、又或是NIC的间接表(Indirection Table)的RX队列数少于CPU核心数,这个时候就需要借助内核的RPS/RFS机制,在软件层面再次进行分配。比如下面的例子,NIC的间接表最大RX队列数只有16
1 | # ethtool --show-rxfh-indir enp7s0f0 |
设置成大于16的值会失败
1 | # ethtool --set-rxfh-indir enp7s0f0 equal 56 |
此时可以使用RPS将16个rx队列再分配到56个核上。
1 |
|
下图很好的描述了上面发生的事情:
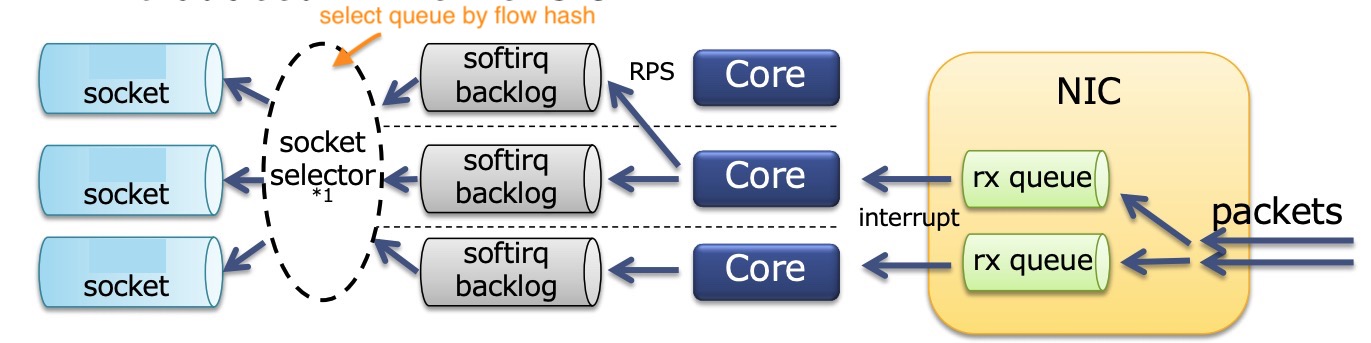
网卡收到包送到多个队列中,然后将队列的中断号与CPU核心绑定,如果没有充分利用CPU,借助RPS再次分配到其他CPU核心上。每个CPU核上有一个ksoftirqd在工作。SO_REUSEPORT解决socket竞争的问题,每个进程有一个独立的socket,默认情况下是对数据流(源和目的的ip端口号)做哈希值来选择送到那个socket。但是这个地方其实还是存在一点竞争,同一个socket可能被不同的核选择,Linux内核从4.5版本起已经支持SO_ATTACH_REUSEPORT_CBPF/EBPF,可以根据核心号来选择socket以消除softirq这里的竞争,配合上进程的CPU亲和性绑定可以最大程度的提升性能。不过Nginx目前还不支持这个选项。